Extreme density and speed: the compute fabric that makes the business factory viable
A payments firm I spoke to in early 2026 had run a proof-of-concept with a popular agent orchestration library. The demo was slick. Fifty agents, fan-out on a batch of contract reviews, results collated in minutes. The infrastructure team then asked the obvious question: what does this look like at a thousand agents? The honest answer came back within a week of profiling: startup latency per container was sitting between two and four seconds, memory overhead per idle workload was several hundred megabytes, and the Kubernetes scheduler was a measurable bottleneck once the fan-out exceeded about two hundred concurrent cells. The numbers did not extrapolate to production scale. The pilot died quietly.
Nobody was surprised. Container runtimes and orchestration platforms were designed in an era when “scale” meant fifty microservices running continuously for weeks. An agent factory runs a different workload entirely: thousands of short-lived, isolated execution environments that must appear in milliseconds, consume almost nothing at idle, and vanish cleanly when the work is done. The economics of the factory depend entirely on closing that gap.
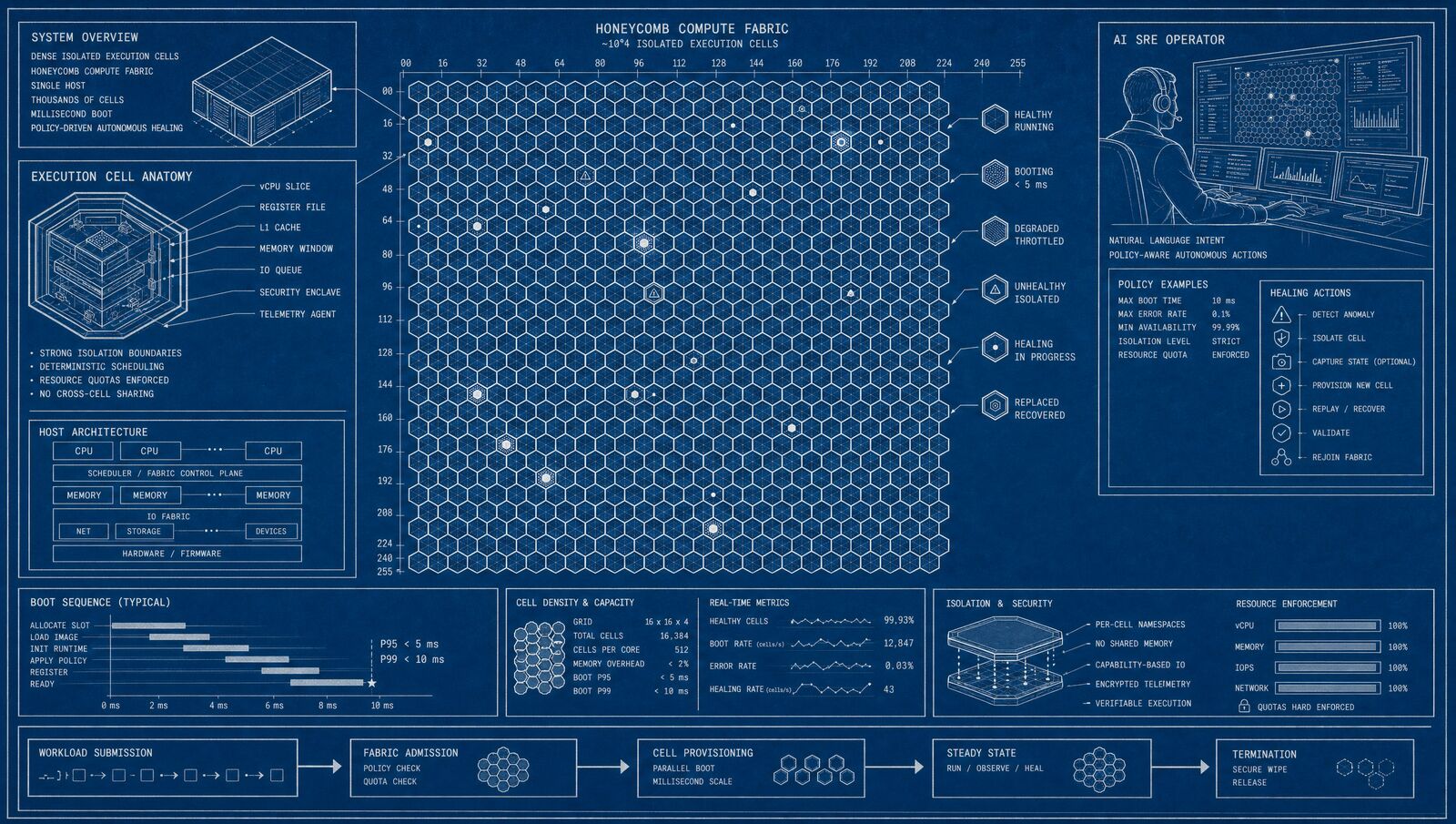
the cell runtime is the Substrate system that closes it. Isolated cells boot in under 50 milliseconds. A single host carries roughly 10,000 idle cells. Build, ship, health-check, and rollback all run under one control plane, and an AI SRE operator monitors the fabric and proposes fixes within policy before the on-call engineer even sees the alert. This post explains why that combination is necessary, how it works, and what it means for the regulated buyers who need to run the factory at scale without an eye-watering infrastructure bill.
The problem with containers for agent workloads
The container as a unit of isolation is a sensible idea that has accrued thirty layers of operational tooling optimised for the wrong workload. When a DevOps team runs a web API, they want it to start once, accept requests for weeks, and be replaced carefully on deploy. The scheduler is tuned for that. Image pull, network namespace allocation, cgroup setup, OCI hook execution: all acceptable one-time costs when amortised over days of uptime.
An agent swarm does not amortise anything. A task dispatch from the mission orchestrator might spin up fifty cells, run each one for ten to thirty seconds, and tear them all down. The next dispatch might need a completely different profile. The cells are bursty by nature. They are also deeply parallel: a factory running a quarterly audit might have several hundred cells live simultaneously, each carrying its own the realtime data plane embedded database, each writing to a shared mission state that other cells are reading in real time. The coordination requirement amplifies the density requirement.
Kubernetes alone does not scale to 10,000 idle pods per node. The etcd watch overhead, the per-pod IP allocation, the kubelet’s reconciliation loop: these are designed for a world where “many pods” means hundreds, not tens of thousands. Cloud-native vendors have pushed back on some of this with virtual kubelet adaptors and node-local schedulers, but the fundamental mismatch between a scheduler designed for services and a workload that looks more like a function runtime remains.
The function-as-a-service world (AWS Lambda, Google Cloud Run, Azure Container Apps) solved part of this problem. Cold-start times have come down considerably over the last two years, and density per host is better than traditional containers. But the FaaS model introduces a different constraint for agent workloads: statelessness. A Substrate agent cell is not stateless. It carries an embedded the realtime data plane database, it maintains live DBSP subscriptions to shared mission state, and it needs to checkpoint and restore with deterministic replay. None of that maps cleanly onto a FaaS runtime.
The AI SRE piece is also missing from every commodity option. A containerised workload that crashes gets restarted by a kubelet probe. That is a blunt instrument. The the cell runtime operator watches the health signal from each cell, correlates it with the task it is running and the realtime data plane state it is holding, and proposes a specific remediation (restart, rollback to a prior snapshot, route work to a sibling cell, escalate to a human gate) within the policy envelope set by the operator. The difference between “the pod was restarted” and “the cell was healed and the task continued without data loss” is the difference between a demo and a production factory.
How the cell runtime works
The cell is the unit. Each cell runtime cell is a lightweight isolated execution environment with a co-located the realtime data plane runtime: storage, execution, and subscriptions in a single process. There is no network hop between the agent logic and the data it reads and writes. The measured figure for agent actions inside a cell is 2,326 per second at 0.43 milliseconds per action on a single node, and that figure is entirely explained by the co-location. Nothing has to cross a socket.
Boot is the number that matters most for an agent factory. The verified figure is under 50 milliseconds for a fully isolated cell, from dispatch to ready. That includes network namespace setup, the realtime data plane runtime initialisation, and the WASM module load. It is fast enough that the mission orchestrator can treat cells as disposable: allocate on dispatch, release on completion. Keep-alive pools are optional, not mandatory. The economics of “boot a cell for every task” close at 50 milliseconds. They do not close at two seconds.
The density figure of roughly 10,000 idle cells per host comes from the combination of the lightweight cell design and the shared-memory architecture of the realtime data plane. An idle cell holds its runtime structures and a minimal database shard. The memory footprint at idle is small enough that a server with a reasonable RAM allocation can hold the order of ten thousand of them. When a task arrives, the cell warms up its specific state from the realtime data plane’s shared structures rather than cold-loading from scratch.
Interactive: watch cells boot under 50ms. Click “inject fault” to trigger a fault in a live cell and observe the heal-and-rollback sequence. Drag the host capacity slider to see density economics.
The build and ship pipeline is owned by the cell runtime alongside the runtime. An agent forge commit triggers a signed build, the output artifact passes through the identity service’s identity verification, and the cell runtime receives a hot-reload instruction. The reload is atomic: the new WASM module swaps in, and on failure the prior version is restored without service interruption. The audit trail for every build, ship, and rollback lands in the realtime data plane event log, which is also the deterministic replay record for the entire factory run. Nothing about operations is a side-channel; the operations themselves are first-class signed events.
The AI SRE operator deserves its own paragraph. It is not a rules-based alerter with a runbook attached. It is a model running inside the cell fabric, with read access to the health telemetry from every live cell, and write access bounded by a policy envelope that the operator has defined. When a cell goes into fault state, the SRE operator classifies the fault (transient crash, the realtime data plane state inconsistency, resource exhaustion, policy violation), selects a remediation action from the permitted set, and executes it or queues it for a human gate if the remediation exceeds the policy boundary. The turnaround from fault detection to proposed fix is typically measured in seconds, not the minutes it takes a rotation engineer to be woken up and read a dashboard.
This is the practical expression of “governed by construction” at the infrastructure layer. The SRE operator does not act outside policy. Its actions are signed by its cryptographic identity. Its decisions land in the same audit log as every agent action. An operator reviewing a post-incident report can reconstruct exactly what the SRE agent saw, what it proposed, and what a human approved or overrode, in the same replay interface used for reviewing the business logic that ran inside the cells.
Density economics: cost per agent-hour
The factory business case rests on a number: the cost per agent-hour at scale. Traditional container-based stacks have three main cost drivers that scale poorly as agent density increases.
First, idle overhead. A container at rest still consumes memory for its filesystem layer, its process table, its network namespace. At a hundred containers on a host, this is a rounding error. At ten thousand, it is the dominant cost line. the cell runtime’s idle footprint is small enough that idle density on a single host reaches five figures; the idle overhead per cell scales toward negligible.
Second, scheduling latency. When a new task arrives and a new cell needs to boot, the time between “dispatch from the mission orchestrator” and “cell ready for work” is dead time the business is paying for. At 50 milliseconds, the dead time on a ten-second task is below 1%. At two seconds, it is 17%. On short tasks, the FaaS cold-start problem is a direct tax on throughput.
Third, operational tooling. Most Kubernetes-based agent setups require a substantial set of supporting services: a logging collector, a metrics server, a separate alerting pipeline, a separate rollback mechanism. Each of these is compute the factory is paying for that contributes nothing to the mission. the cell runtime collapses these into the control plane and the AI SRE operator, with the operational telemetry living inside the realtime data plane rather than in a separate observability stack.
The net effect, illustrated with illustrative numbers: a factory running a thousand concurrent agent cells on the cell runtime requires roughly a tenth of the host count it would need on a standard containerised stack, because the density difference is an order of magnitude. The operational staffing required to keep it running is also reduced, because the AI SRE operator handles the majority of fault scenarios without human intervention. The business case for the factory at scale is not primarily a model cost story; it is an infrastructure cost and operational overhead story, and the cell runtime is the system that makes the numbers work.
Cold-start versus keep-alive
There is a real engineering decision inside any high-density agent runtime about when to use cold-start and when to maintain a pool of warm cells. the cell runtime supports both, and the mission orchestrator decides which to use based on the mission budget and the task profile.
For short tasks with unpredictable arrival patterns, cold-start at 50 milliseconds is the right answer. There is no point holding warm cells in reserve if the arrival rate is irregular and the task duration is short enough that the boot latency is negligible. The cells boot, do the work, and release.
For high-priority tasks where latency matters, or for tasks that belong to a long-running mission where cell warm-up context is expensive to rebuild, keep-alive makes sense. the mission orchestrator tracks the per-mission cell pool and decides, within the hard budget for the mission, how many warm cells to hold. A mission running a continuous audit process might maintain a small pool of pre-booted cells ready to handle incremental work as it arrives. A burst mission (a quarterly report run overnight) boots fresh cells on demand.
The key insight is that this decision is made by the budget, not by an infrastructure configuration file. the mission orchestrator meters the cost of keeping cells warm (memory allocation, power, per-cell licensing) against the latency benefit for the task profile, and picks the cheapest approach that still satisfies the latency requirements. The operator does not tune a pool size. The operator declares a budget and a mission, and the factory chooses the infrastructure strategy to match.
That is the same principle that governs model routing in the mission orchestrator: cheapest-sufficient. At the compute layer, it means the mission gets exactly the density it needs, at the cost the budget allows, and no more. The factory does not over-provision unless it is paid to.
Integration with the mission orchestrator task dispatch and the realtime data plane state
the cell runtime does not run in isolation. Its integration with the mission orchestrator is tight by design.
When the mission orchestrator decomposes a mission into tasks, each task carries a cell profile: the WASM module to load, the realtime data plane state namespace to mount, the memory allocation, and the policy envelope for the AI SRE operator. the mission orchestrator hands this profile to the cell runtime’s scheduler along with the task payload. The scheduler resolves the profile to a cell (booting a new one or claiming a warm one from a keep-alive pool), mounts the realtime data plane namespace, and marks the task as running. The whole handoff is sub-50 milliseconds.
Inside the cell, the realtime data plane runtime provides live state that all cells in the same mission share. A cell running a document analysis task writes its findings into the shared mission namespace. A cell running an entity-graph update reads those findings via a DBSP subscription and reacts to the delta without polling. The shared-state model means that coordination between cells does not require a message queue or an external database; it happens through the same the realtime data plane runtime that is providing sub-millisecond action latency.
When a cell completes its task, it writes a signed completion event to the realtime data plane, the mission orchestrator reads the event and dispatches the next downstream task, and the cell either releases its resources or enters the keep-alive pool based on the mission profile. The entire sequence is deterministically replayable. A post-mission replay shows every cell boot, every task dispatch, every state write, and every completion, timestamped and signed by cryptographic identity of the cell that produced them.
Interactive: this diagram shows the owned compute fabric running inside the customer’s walls. Toggle “simulate provider outage” to see the factory continue running on owned models. Toggle “air-gap mode” to remove the external link entirely.
The combination matters because it means operational incidents and business-logic issues are traceable in the same record. If a cell healed and rolled back during a mission, that event is in the same log as the agent actions that preceded the fault. An audit of the mission output can show not just what the agents decided but whether any cell had an incident during the run, what the SRE operator did, and whether any human gate was required. That level of reconstruction is not possible when the operational layer is separate from the execution layer.
A sector walkthrough: healthcare claims processing
A health insurer processing prior-authorisation requests faces a specific version of the density problem. The inbound volume is spiky: submissions cluster around the start of the working day and again after lunch. The individual cases are short-lived tasks (extract the clinical data, check against the relevant formulary, apply the policy rules, flag exceptions) but there can be several thousand arriving in a two-hour window.
Before the factory, the infrastructure for this looked like a queue feeding a fixed pool of worker containers. The pool size was set to handle the peak load, which meant it was over-provisioned for most of the day. Cold-start latency on the containers was acceptable because the pool was always warm, but that warmth cost money continuously.
With the cell runtime, the pool size becomes a budget decision made by the mission orchestrator. At off-peak times, the cell count drops to a minimal keep-alive floor. At peak, the mission orchestrator dispatches cold-boot cells to absorb the volume, and the 50-millisecond boot time means the ramp-up completes before the queue has had time to build meaningfully. The peak handling cost is paid only at peak. The baseline cost drops.
The clinical decision logic runs inside realtime data plane cells. Every policy check is signed by cryptographic identity of the cell that ran it. Every exception surfaces to a named clinician approval gate via the mission orchestrator. The evidence pack assembled by the mission, with lineage back to the source submission and every intermediate decision, is ready by construction when the clinician opens the case. Nothing needs to be reassembled for audit.
The insurance regulatory environment (in the UK, the FCA’s operational resilience framework; in the US, CMS requirements for claims processing transparency) increasingly requires exactly this kind of evidence. The fact that it is produced as a side-effect of the factory’s normal operation, rather than assembled retrospectively by a compliance team, is the economic win. The compliance cost is not a separate line item. It is zero incremental overhead because the infrastructure that does the work also produces the signed record that proves it.
This is the “software then everything else” claim made concrete. The same the cell runtime fabric that boots cells for a code-writing mission (see one-binary agent runtime in the realtime data plane) is the fabric that boots cells for a claims-processing mission. The economics, the density, and the operational properties are identical. Only the WASM module and the realtime data plane state schema change.
What keeps the sovereign story together
The density and speed numbers are interesting on their own. What makes them strategically significant is that they hold inside the customer’s walls, without depending on a cloud provider’s managed container service.
A factory that relies on a hyperscaler’s managed runtime for its density properties is a factory that can be repriced, capacity-constrained, or taken offline by a single vendor’s decision. For regulated buyers in finance, healthcare, and government, that dependency is not theoretical. CLOUD Act exposure, data residency requirements, and EU AI Act compliance obligations have made “where does the compute run and who controls it?” a board-level question, not a DevOps detail.
the cell runtime runs on bare metal, on-premises, or in a private cloud. The density it achieves is a property of the cell design, not of a managed service underneath it. A UK financial regulator can mandate that the factory processing its authorisation data runs within UK infrastructure: the factory runs unchanged. A government department can operate an air-gapped deployment: the cell runtime still delivers the same sub-50ms boot and the same 10,000-cell density, because neither number depends on an external API.
The AI SRE operator runs inside the same perimeter. It does not call home to a monitoring SaaS. Its telemetry is stored in the realtime data plane. Its remediation actions are bounded by the policy that the on-premises operator set. The operational loop is closed inside the customer’s walls, and the record of every SRE action is in the same audit trail as the business logic.
This is what the sovereign section of the Substrate homepage means when it says “runs on your hardware.” It does not mean “we have a bring-your-own-cloud option with some features missing.” It means the full factory, at full density, with the full operational capability, inside the perimeter you control. The deployment story for the compute fabric and the deployment story for the sovereign AI platform are the same story. The compute is not separable from the sovereignty.
For a deeper look at how the sovereign deployment story works across the full stack, sovereign AI: air-gapped by default covers the cell runtime, the realtime data plane, and the governed memory engine sovereign deployment in detail. The hardware economics of the agentic wave, and why the density the cell runtime achieves matters so much for capex planning at scale, are covered in hardware implications of the agentic wave.
What to demand in an RFP
If you are evaluating a compute fabric for an agent factory in a regulated environment, the questions that separate serious platforms from interesting demos are straightforward.
Ask for the actual boot latency, not the “typical” or “warm” boot time. You want the time from task dispatch to cell ready for work, cold, including all the setup that a production cell requires: namespace isolation, runtime initialisation, module load, state mount. Get a distribution, not a headline number. The 50-millisecond figure for the cell runtime is the end-to-end time on a production-representative cell profile.
Ask what happens at 10,000 concurrent cells on a single host. Not in a managed cloud (where the host is abstracted away) but on a bare-metal server you can inspect. Ask for the memory profile, the scheduler latency under load, and the CPU overhead of the control plane. Numbers that look good on one host often look very different when the scheduler itself is under load.
Ask how the operational loop works. Specifically: when a cell faults, what is the sequence of events? Who or what detects it, what is the time to proposed remediation, what actions are permitted without human approval, and where does the record of the incident live? If the answer involves a separate monitoring tool writing to a separate datastore that an on-call engineer checks on a dashboard, you have discovered that operations and execution are separate concerns with separate records and a gap between them that will matter during an incident.
Ask whether the compute fabric runs identically in an air-gapped, on-premises deployment. Some density and operational properties are properties of the managed cloud service, not of the compute design. If the air-gapped version degrades meaningfully (longer boot times, lower density, no AI SRE, manual rollback) you are buying a cloud product with a sovereign mode bolted on. That is a different product from a factory designed to run inside the customer’s walls from the beginning.
A 90-day pilot
The fastest way to validate the compute economics is a narrow, high-volume regulated workflow. Claims processing, document intake, trade-reconciliation batches: any workflow with a known inbound volume, a measurable per-item cost today, and a clear definition of “done” that includes a compliance record.
Run it on the cell runtime for 90 days. Three numbers tell the story: peak throughput (what is the maximum cells-per-minute the cell runtime dispatched, and how does that compare to the prior infrastructure’s capacity ceiling?), idle cost (what did the compute cost per hour during off-peak, as a fraction of the prior always-on pool?), and incident rate (how many cell faults occurred, how many were resolved by the AI SRE operator without human intervention, and how long did each resolution take?).
The fourth number, which you may not have had before, is the audit overhead: how much time did your compliance team spend assembling evidence for the period’s cases? In a factory that produces signed records by construction, that number should approach zero. If it does not, you have found a gap in the implementation worth investigating.
The combination of density, speed, and operational completeness is not the only thing that makes the cell runtime significant. It is significant because those properties hold together inside the perimeter, at the scale the factory needs to be economically viable, without a dependency on a managed cloud service that a regulated buyer cannot accept. The factory is only as good as the floor it runs on. This is the floor.
If the compute and economics story is where you want to start the conversation, you can request the investor brief for the full technical and financial picture. The coordination patterns that run inside the cells, and why embedded state eliminates the race conditions that plague queue-based multi-agent systems, are covered in multi-agent coordination without races.