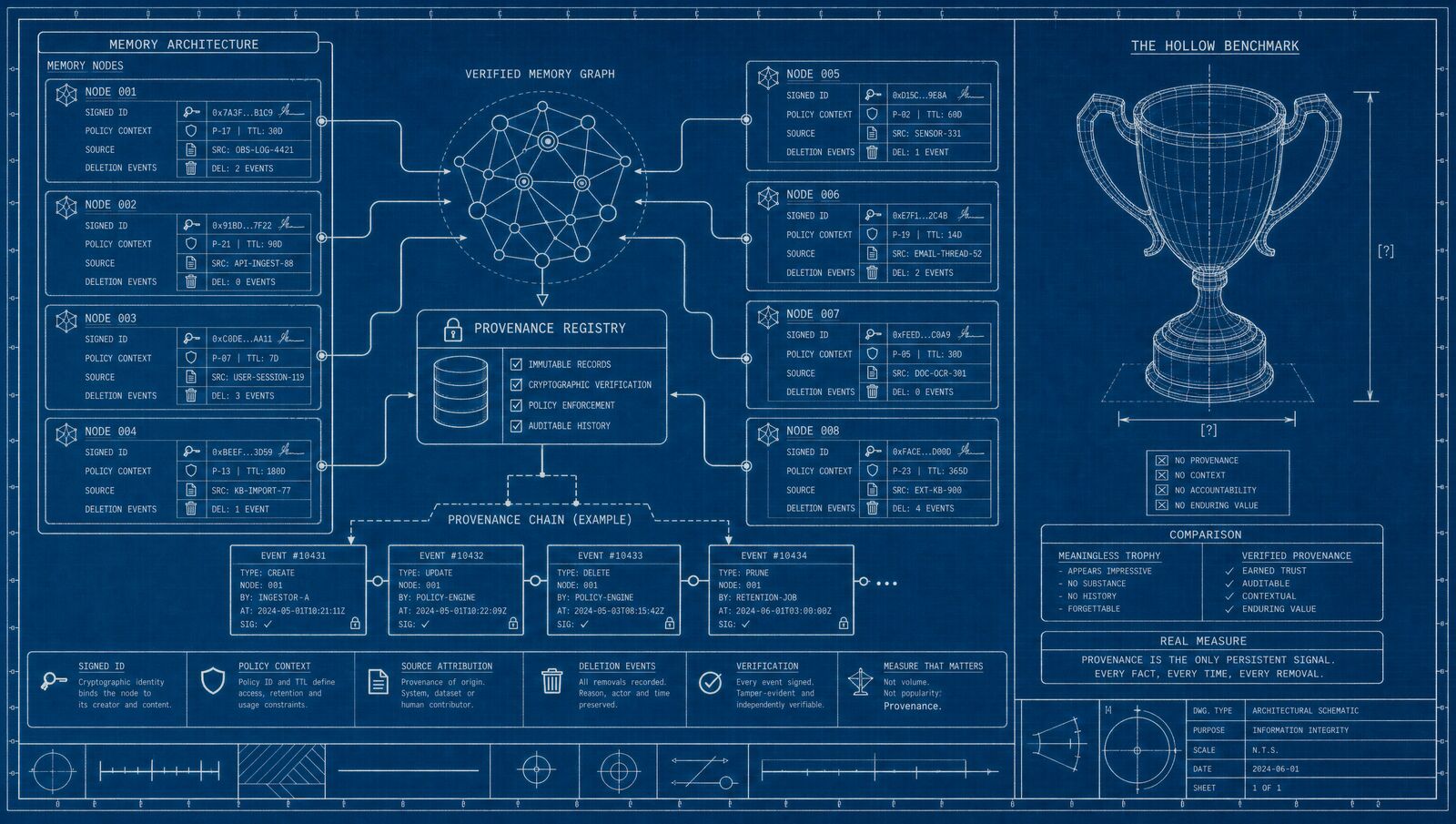
Provenance, not recall accuracy, is the real differentiator
A chief risk officer at a large European bank told me something that stuck. Her team had shortlisted three agentic memory systems for a DORA-compliance project. Two of them had impressive scores on LoCoMo and similar recall benchmarks. The third had middling retrieval performance but could produce, on demand, a signed record showing exactly which agent wrote each memory node, under what data-handling policy, from which source document, and whether any of those nodes had subsequently been deleted. Her team picked the third one. The other two could not pass their first-round audit gate, and their retrieval scores never even came up.
That is the story this article is about. It is not a story about bad benchmarks. It is about the gap between what benchmark authors optimise for and what regulated buyers actually need to go live.
The benchmark problem stated plainly
LoCoMo (Longitudinal Conversation Memory) tests whether a system can correctly answer questions about events discussed in long conversational histories (source: LoCoMo dataset, Maharana et al., EMNLP 2024). BEAM, MAGMA, and similar 2025-2026 evaluation suites extend this to multi-session and multi-document settings. These are legitimate research contributions. They stress-test retrieval depth, temporal ordering, and contextual recall in ways that earlier benchmarks did not.
What they do not test is this: can the system tell you, for any given retrieved memory, who created it, when, under what policy, from what original source, and whether a subsequent deletion event has occurred? Those questions are not retrieval questions. They are provenance questions. And for a regulated buyer, provenance is the precondition for any retrieval result being usable at all.
Think about what a CRO actually needs from an agent memory system deployed in a credit decisioning workflow. The retrieval accuracy matters. Of course it does. A system that hallucinates or misattributes facts is a liability. But a system that retrieves correctly and cannot then prove the provenance of the retrieved facts is equally a liability, just a less obvious one. The regulator does not ask “did your system recall accurately in 85% of test cases?” The regulator asks “show me the decision, the data it was based on, who produced that data, when, and under what authorisation.” A high recall score is silent on every one of those questions.
The benchmark leaderboard tells you a lot about a system’s performance in a research context. It tells you almost nothing about whether the system is deployable in a regulated context. The two are not correlated in any useful way.
What provenance actually means in a memory graph
Provenance in an agent memory system is not a field in a database. It is a set of guarantees that must hold for every node the system has ever created, modified, or deleted, across its entire operational lifetime.
The minimum viable provenance record for a regulated deployment has five components.
Signed agent identity. The creating agent’s identity must be cryptographically bound to the memory node at write time. Not a username. Not an API key stored in a config file. A verifiable, non-repudiable signature from an agent that has a provable identity lifecycle: registered, active, suspended, or revoked. If you cannot prove which agent signed the write, you cannot defend the node in an audit. The identity plane that handles this in Substrate is the identity service. Every agent in the factory carries an Ed25519 identity issued by the identity service, and every memory write carries a signature that binds the agent’s current identity state to the written content.
Policy context at write time. The policy under which the memory was created must be captured at creation, not inferred retrospectively. If the system’s data-handling rules were version 4 at the time of write and are now version 6, the node must carry a record of the version-4 policy it was written under. Reconstructing policy context after the fact is not the same as capturing it at the time, and a regulator performing a retrospective audit will notice the difference.
Source attribution. The origin document, feed, or upstream agent output that was the input to this memory must be traceable. This is what makes a memory graph defensible rather than plausible. You can retrieve a fact about a counterparty’s risk classification. But if you cannot trace that fact back to the specific document version, ingestion timestamp, and chain-of-custody from source to node, the fact is anecdotal from an audit perspective. OAMP (the Open Agent Memory Protocol) formalises this in its provenance fields, which include source_uri, ingestion_policy, and originating_action_id alongside the identity fields.
Temporal bounds. The valid time and transaction time of the memory must be explicit, not derived. When did this fact actually hold? When did the system learn it? A bitemporal memory design (as in the governed memory engine) separates these two axes so that you can answer questions like “what did the agent know about this entity on the 14th of March, as of the record state that existed at that time?” without ambiguity. This is the “as of” query that auditors use routinely in financial and healthcare contexts, and it requires bitemporal structure to be answerable correctly. The sister article Bitemporal memory as the compliance backbone goes into this in considerably more technical depth.
Deletion events. When a memory node is deleted, the deletion must be a first-class event in the provenance record. Not a database vacuum. Not a soft-delete flag that “might” get cleaned up. A signed, policy-attributed record that this node was removed, when, by which agent, under what authorisation, and that downstream nodes which depended on it have been appropriately handled. This is the GDPR Article 17 requirement applied to agent memory: the right to erasure means the system must be able to demonstrate that the erasure happened, not just assert that it did. The article on hard-delete and governance by omission covers the cryptographic mechanics in full.
None of these requirements appear in any major memory benchmark as of mid-2026. That is not a criticism of the benchmark authors, who are solving a different problem. It is a statement about the gap between research evaluation and regulated deployment.
The hash chain as the provenance substrate
Interactive: hover any block to inspect the full provenance fields attached to that memory write event. Toggle “simulate tamper” to see how altering a single field invalidates the entire downstream chain, making evidence of tampering immediate and unambiguous.
The diagram above shows what provenance looks like when it is built correctly. Each block represents a memory write event: an agent action that either creates a new node in the memory graph or updates an existing one. The blocks are chained via their hashes. Each block commits to the hash of the previous block, which means any retroactive alteration of a block’s content, including its provenance fields, produces a broken chain that any verifier can detect.
This is not a novel data structure. Hash-chained event logs are standard in systems that need tamper evidence. What is novel in Substrate’s implementation is the integration of provenance fields directly into the signed block content, rather than treating them as metadata attached after the fact. When the governed memory engine writes a memory node, the write event that lands in the identity service’s append-only log carries the full provenance record as part of the signed payload. The agent identity, the policy version, the source attribution, the temporal bounds: all of these are inside the signature boundary. Changing any one of them would change the block’s hash and break the chain.
The practical implication is that the provenance record is not a separate audit system running alongside the memory system. It is the memory system. Every recall event also consults the provenance chain. When an agent retrieves a memory node, the retrieval carries the provenance metadata alongside the content, so the agent can reason not just about what the fact says but about how trustworthy the fact is: how recent, under what policy, from what source. This is important for avoiding a subtle class of errors where agents treat a memory node that was written under an outdated policy as having the same epistemic status as one written under the current policy.
The tamper toggle in the diagram illustrates a property that never shows up in a recall benchmark: detection of retroactive manipulation. In a regulated context, an agent swarm that processes sensitive decisions creates records that have legal significance. The integrity of those records is therefore a target. A flat vector store offers no structural guarantee against a database administrator altering a record after the fact. A hash-chained log with signed provenance fields makes any such alteration detectably inconsistent with the chain, which is the structural property that lets you tell a regulator “we can prove this record has not been altered since it was created.”
What a flat vector store cannot produce
Interactive: toggle “show glue-stack gaps” to see which provenance artifacts a flat vector store with standard tooling cannot produce. Hover any workflow step to inspect the specific audit artifact it emits and which system in the Substrate factory is responsible for it.
The second diagram walks through a memory workflow in a regulated context and shows the provenance artifacts that each step must produce to satisfy an audit. The toggle reveals what a typical glue-stack approach, a vector store plus an orchestration framework plus a relational database for logging, cannot produce even in principle.
The gaps are not gaps in implementation. They are gaps in design. A vector store does not have an agent identity plane. It cannot sign a write with a cryptographic identity because it has no concept of agent identity. You can log writes to an adjacent database, but that adjacent database is a separate system with a separate trust boundary. An auditor performing forensic analysis on a breach or a disputed decision has to trust that the log was written correctly and has not been modified, and that trust has to rest on something other than “we have admin controls on the database.” In a serious regulated inquiry, that is not enough.
A few specific gaps are worth naming.
Agent identity at write time is absent in all major vector stores as of mid-2026. Pinecone, Weaviate, and similar systems offer API key authentication, which identifies the client application but not the specific agent within that application. If your swarm has twenty agents writing to a shared vector store, you cannot determine from the store itself which agent wrote which record. You can add application-layer logging, but application-layer logs are outside the trust boundary of the store.
Policy version at write time is similarly absent. Vector stores do not have a concept of data-handling policies. You can store policy metadata in a vector store, but you are relying on the application to write it correctly, and the application is not a signing authority.
Deletion provenance is the most significant gap. Vector stores support deletion. What they do not support is a signed, policy-attributed record of the deletion event that is cryptographically bound to the original write event. GDPR Article 17 compliance requires demonstrating that a deletion happened, not merely that the current state of the store does not contain the deleted record. Without a hash-chained deletion event, you can show absence but not proved erasure.
The OAMP specification addresses these gaps by defining a minimum provenance contract that any compliant memory implementation must satisfy. the governed memory engine implements OAMP natively. The provenance fields in OAMP include agent_identity (the issued by the identity service identifier and signature), policy_id and policy_version at time of write, source_uri and source_hash for attribution, valid_from and valid_to for temporal bounds, and deletion_event with its own signature chain when applicable. An OAMP-compliant query response does not just return the memory content; it returns the full provenance record as an inseparable part of the response. This is what makes it possible to build a query layer that reasons about provenance quality, not just retrieval relevance.
The deeper point is about what “governed by construction” means for memory. The Substrate homepage uses that phrase to describe the factory’s overall audit posture: every action is signed and auditable by construction, not because someone bolted an audit trail onto the side of an existing system, but because the systems were designed from the start to make every operation an auditable event. Memory is no different. In the governed memory engine, provenance is not a feature; it is the design constraint that shaped the entire data model.
A sector walkthrough: healthcare clinical coding
Suppose you are deploying an agent swarm to assist clinical coders in a National Health Service trust. The swarm ingests discharge summaries, assigns ICD-10 and OPCS codes, flags ambiguities for human review, and outputs a coded record that feeds into the Payment by Results tariff calculation. This is a high-stakes workflow: incorrect coding affects the trust’s income, and in serious cases it can affect clinical governance.
The memory component of this system is doing real work. Agents are building and refining a memory graph of patient pathways, coding patterns, consultant preferences, and policy rules specific to the trust’s specialties. Over time, that memory graph becomes a significant institutional asset. It also becomes a significant regulatory exposure if it cannot be audited.
Under the current arrangement, a clinical coding team lead is reviewing a disputed code assignment. The agent that made the assignment retrieved a memory node describing a coding convention for a particular comorbidity pairing. The team lead needs to know: when was that convention written into the memory graph? By which agent, under what version of the trust’s coding policy? Was it derived from NHS Digital guidance, from a consultant’s preference captured in a prior session, or from some other source? And has anything happened to that node since it was written, including any deletion events?
With a flat vector store, the honest answer to most of those questions is “we do not know.” The store holds the content. It does not hold the provenance chain. The team lead is looking at a retrieved fact with no lineage.
With the governed memory engine and the OAMP provenance fields, the team lead can answer every one of those questions from the memory system itself. The agent that wrote the convention is identified by its cryptographic identity. The policy version at write time is part of the signed block. The source is attributed to its NHS Digital guidance document version and ingestion timestamp. The temporal bounds are explicit. And if the convention has been superseded by a newer policy, the supersession event is in the chain.
The before and after here is stark. Before: a team lead conducting a dispute review is working from retrieved facts with no verifiable lineage, relying on informal knowledge of when certain conventions were introduced and trusting that the memory system is consistent. After: the same review starts from a provenance record that is as auditable as the clinical record itself. The dispute resolution time falls, the audit defence improves, and the governance posture of the deployment changes from “plausible” to “defensible.”
What is notable about this sector walkthrough is that the provenance requirement does not change the recall mechanism. The agents are still doing spreading-activation retrieval across the memory graph. The queries are still resolved in approximately 3 ms. The only thing that changes is the audit trail attached to every node the retrieval touches. In a well-designed system, provenance is not a tax on performance; it is an output of the write path that comes for free at query time.
What to demand in an RFP
If you are evaluating agentic memory systems for any regulated deployment, the questions below will separate systems that can survive an audit from systems that can only survive a benchmark.
Ask the vendor to demonstrate a complete provenance record for a single memory write. Not a diagram of the intended design. An actual query response showing the agent identity, policy version, source attribution, temporal bounds, and signature for a node that was written during a live demonstration. If the vendor cannot produce this in real time, the system does not have it.
Ask what happens to the provenance record on deletion. The correct answer is that the deletion creates a new signed event in the provenance chain, that this event is cryptographically bound to the original write event, and that the system can demonstrate the deletion to a third-party verifier without the verifier needing to trust the vendor’s claims. Any answer that involves “we log deletions to a separate audit table” is not sufficient for GDPR Article 17 compliance in a forensic context.
Ask how the system handles policy version changes. If data-handling rules change after a memory node was written, can the system retrieve the policy that governed the write, not just the current policy? This is the bitemporal equivalent for policy state: what did the system believe the rules were, at the time it acted? If the vendor cannot answer this, they are not equipped for the kind of retrospective audit that financial regulators and healthcare governance bodies routinely conduct.
Ask about OAMP compatibility. OAMP defines an interoperability contract for agent memory that includes the provenance fields discussed here. A vendor who is unfamiliar with OAMP is probably building a proprietary system with proprietary provenance handling, which creates vendor lock-in at exactly the layer where interoperability matters most. The article on OAMP as the interoperability layer goes into the why of this in more detail.
Ask to see the system’s behaviour on the benchmark suites you care about, by all means. But treat benchmark scores as a floor, not a ceiling. A system that scores well on LoCoMo but cannot produce provenance records is a research artefact. A system that has provenance built into its data model and also retrieves well is a production system.
A 90-day pilot design
The right pilot for a regulated buyer has two tracks running in parallel from the start.
Track one is the retrieval quality track. Pick a representative sample of the queries your workflow will generate. Measure recall precision and latency against a held-out evaluation set that you control, using data drawn from your actual domain. Do not rely solely on published benchmarks, because your domain may have distribution properties that differ from the benchmark corpus.
Track two is the provenance audit track. From day one, define the provenance questions your governance team will need to answer. Map them to the OAMP provenance fields. Run a sample audit against live memory nodes after the first two weeks of operation and check whether the provenance records are complete, whether the signatures verify, and whether the deletion chain is intact for any nodes that have been deleted. This track is what determines whether you can go to production, and it is the one that most pilot designs omit entirely.
The reason both tracks matter is that they can fail independently. Track one tells you the system is useful. Track two tells you the system is deployable. You need both. A system that passes track two but fails track one is an audit-ready system that nobody wants to use. A system that passes track one but fails track two is an impressive demo that you cannot put in front of a regulator.
If you run both tracks and both pass after 90 days, you have the evidence you need to make the case to your governance committee. The provenance records from the pilot are themselves the audit-ready artefact: signed, chain-verified, with deletion events intact. You are not describing what the system will do in production. You are showing what it did in the pilot, in a form that can be independently verified.
The real competitive question
The market has spent considerable energy on recall leaderboards. That energy is not wasted. Better retrieval is genuinely useful, and the research community is doing important work. But for the CRO, the head of internal audit, and the VC doing diligence on a regulated AI deployment, recall accuracy is not the axis that determines whether a system is viable.
The question that separates viable from non-viable is simpler and harder to fake: can the system show me, for any fact it retrieved and acted upon, exactly where that fact came from, who put it there, under what authorisation, and what happened to it subsequently?
A system that can answer that question has provenance. A system that cannot, regardless of its benchmark ranking, is asking you to trust it without giving you the evidence to verify that trust. In a regulated context, that is not a product. It is a liability with a nice API.
The Substrate factory approaches this differently by design. the governed memory engine’s data model treats provenance as a write-time constraint, not a post-hoc annotation. the identity service’s identity plane makes every write attributable to a specific, verifiable agent identity. OAMP’s provenance fields define the interoperability contract so that provenance depth is portable, not locked to a single vendor. And the hash-chained log ensures that the provenance record itself is tamper-evident.
These properties do not appear on recall leaderboards. They appear on audit reports. For the buyers who matter in regulated verticals, that is the right place for them to show up.
If you want to see how provenance connects to the factory’s broader audit posture, the article on cryptographic agent identity and the identity service covers the identity layer in more depth, and what regulated buyers should demand in memory benchmarks extends the evaluation framework to the full set of governance requirements. Both are worth reading alongside this one.
To see how this works in the context of the whole factory, you can request the investor brief or speak to the team directly.